안녕하세요, 조교입니다.
최근에 diffusion model이 뜨거운 감자라 VAE를 설명하면서 이와 연관된 개념인 diffusion model에 대해 설명드리도록 하겠습니다.
먼저, Denoising Diffusion Probabilistic Models (DDPM)이라는 Janothan Ho의 논문으로 diffusion model은 탄생하게 되었는데, 이 모델은 결국 VAE에서 하던 일을 random variable의 개수를 극한으로 늘리고 성공적으로 training시키면 (그에 대한 loss는 새롭게 디자인함) 좋은 sample generation을 할 수 있다는 것을 최초로 보인 모델입니다.
여기서 주목할 만한 점은, random variable의 개수는 왜 많아야 하는가? 입니다. 사실 DDPM의 성공에 힘입어 Yang Song의 score-based generative modeling through stochastic differential equations 논문에서는 random variable의 개수를 무한대로 늘린 diffusion model은 확률미분방정식으로 표현된다는 것을 밝혔는데, 그 반대 방향인, random variable의 개수를 줄이게 되면 어떤 일이 일어나는지는 알려진 바가 거의 없습니다. 하여, 이번시간에는 Tackling the Generative Learning Trilemma with Denoising Diffusion GANs에서 소개된 내용을 말씀드리도록 하겠습니다.
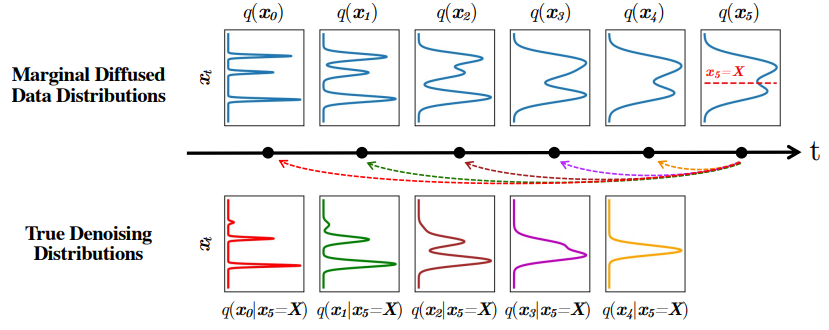
아래 그림은 해당 논문에 나온 그림입니다. diffusion model은 기본적으로 inference distribution인 q(x_{t-1}\vert x_{t})q(xt−1∣xt) 를 (parametrized) generative distribution인 p_{\theta}(x_{t-1}\vert x_{t})pθ(xt−1∣xt) 로 추정하는 것인데, p_{\theta}(x_{t-1}\vert x_{t})pθ(xt−1∣xt) 는 Gaussian 분포로 모델링 하였습니다. 아래 그림에서 True denoising distribution을 tractable하게 1차원에서 계산한 그림을 보면, q(x_3\vert x_5=X)q(x3∣x5=X) 부터 q(x_0\vert x_{5}=X)q(x0∣x5=X) 까지의 분포는 모두 Gaussian 분포와 많이 다른 것을 관찰하실 수 있습니다. 반면, q(x_4\vert x_5=X)q(x4∣x5=X) 는 유일하게 Gaussian 분포와 유사한데, 그렇기 때문에 t를 잘게 쪼개어 학습해야 diffusion model의 model distribution이 true data distribution에 가깝게 학습될 수 있습니다. 이것이 diffusion model에서 왜 random variable의 개수가 많아야 하는지를 설명해줍니다.
comment